
The AI Plateau Illusion
What Corporations and Senior Decision Makers Can Expect from the Next Generation of AI Models

If you, like me, were involved in corporate strategy and long-term planning in the early 2010s, you would have noticed that 2020 was anticipated to be a special year. It was the year when many of our wildest business dreams were expected to come true. I coined the phrase—that turned out to be false—that "in 2020, we would live in the future," implying that innovations we expected in the distant future would already exist. Instead, we got a pandemic.

The Road to the Future
Fast forward to 2024, and there are signs that the future has arrived. As William Gibson, the American-Canadian fiction writer and author of the cyberpunk novel Neuromancer, is attributed to have said, “The future is already here — it's just not evenly distributed.” We can guess where that future is, though—in the secret lab of the leading generative AI company, OpenAI.
In this article, I will focus on OpenAI, which I currently consider the leader in generative AI development, despite its recent dethroning by Anthropic’s Claude 3.5 Sonnet. However, I have tempered my expectations. In my 2024 prediction, I estimated OpenAI to be roughly 12 months ahead of its nearest competitor. Now, I believe the gap is closer to six months. Estimating this is challenging, though, as all major AI companies have faced significant struggles this year.
OpenAI’s CEO, Sam Altman, enjoys trolling the market—a luxury you can afford as an obscure non-profit organization. This behaviour makes it difficult to interpret their next moves and distinguish genuine signals from trolling. We expected an updated model, GPT-4.5, in late December last year, but it never materialized. At the time, I speculated that OpenAI had the option to release the model depending on the strength of Google's then-announced Gemini Ultra model. Now, I believe the primary reason we didn't see GPT-4.5 was a matter of compute. Their strategic partner, Microsoft, couldn't supply the necessary hardware—specifically, enough of NVIDIA’s H100 graphic processing units—to support a compute-heavy 4.5 model while simultaneously developing future models. That, and the turbulence that followed when the OpenAI board, in November, hit the corporate self-destruction button and subsequently ousted Sam Altman during the course of a weekend. Before he made a Jesus-like comeback after the third day.
On May 13, 2024, a day before Google’s major developer conference, Google I/O, OpenAI launched a new model, GPT-4o. The “o” stands for “omni,” indicating its capability to work across audio, vision, and text in real time. This multimodality enables more natural human-computer interactions. OpenAI made little secret of its inspiration from the fictional AI model “Samantha,” played by Scarlett Johansson, in the 2013 movie Her.
I have previously asserted that we shouldn't worry too much about AI taking all our jobs as long as there remains some value we can add to each other. The real concern arises the day you go to a coffee shop with friends, and everyone places their phones on the table, letting the AIs talk to each other while the humans just listen. Based on the demos we've seen, with the GPT-4o voice module (as of writing not yet released) that day could be surprisingly imminent.
Despite this, GPT-4o will not be the model to take all our jobs primarily because it is a small, albeit fast, model available for free to everyone. My take is that GPT-4o is the replacement for GPT-3.5 but with the user interface of GPT-5. This mirrors the OpenAI strategy from November 2022, when they released GPT-3.5 with the GPT-4 interface before launching GPT-4 four months later. I expect a similar approach this time.
The release of GPT-4o left me puzzled, though. Why didn’t they focus on the next frontier model, GPT-5, or whatever it will be called? Now, paid users have access to the same model available for free to everyone else. To understand how OpenAI got into this situation, we need to examine AI development from first principles.
Understanding the Development of AI from First Principles
Leopold Ashenbrenner is a hyperintelligent AI researcher who graduated as the top student from Columbia University at the age of 19, three years ago. Apparently a loose cannon, his dismissal from OpenAI’s long-term safety team, the so-called super-alignment team, was unsurprising. I mention him because he has recently been an insider at the leading AI lab. By turning down a $1 million equity deal, he is also free to discuss his experience. He has done so through a well-written 165-page report on AI development. While there are a lot to disagree about in it, I believe he has effectively captured the underlying mechanisms of AI progress.
To understand AI progress, it helps to understand what it is not. Many people erroneously compare AI development to the evolution of the iPhone. They equate GPT-3 to the iPhone 3GS, GPT-4 to the iPhone 4, and GPT-5 to the iPhone 5, envisioning a progression leading to an iPhone 15 that is more powerful but still familiar. The iPhone 15 Pro has a GPU compute capacity of up to 2.1 TFLOPS, and by 2030, I expect this might increase 2x. Leopold Ashenbrenner argues that the corresponding increase in AI during the same time could be 1,000,000,000,000,000x, in comparison to GPT-4 at launch. Even if he overestimates that by a factor of a million, it is still unimaginable what such a system would look like. It certainly wouldn't be a chatbot.
The key to understanding AI progress is recognizing that it is exponential, and hence measured in orders of magnitude (OOMs). One OOM represents a 10x improvement, two OOMs represent a 100x improvement, and so on. According to Ashenbrenner, AI development is driven by three cumulative factors: scaling of physical compute, algorithmic progress through efficiencies, and algorithmic progress through unhobbling.
The first factor, physical compute, combines faster chips, which improve according to Moore’s Law, and the expansion of data centres. This currently results in an approximate 5x increase, or 0.5 OOMs, per year.
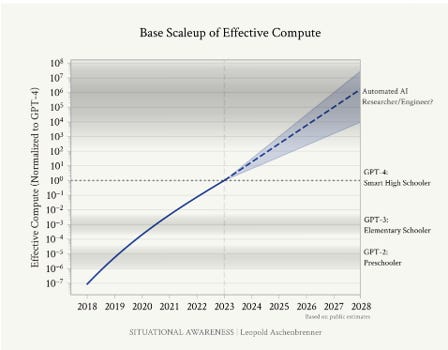
Additionally, efficiencies can be found in smarter algorithms, enabling AI models to learn faster from less data. Numerous research papers on this topic are published every day, potentially contributing another 0.5 OOMs per year.
Furthermore, we can unlock more potential from AI models by using them in smarter ways, a process here called unhobbling. For example, the first version of GPT-3 would respond to "hi" with just similar words like "hi there, hello, greetings." Without making the model as such smarter, the creation of the chat interface in GPT-3.5 unlocked a new level of value. A similar step-change is expected when chatbots are upgraded to AI agents.
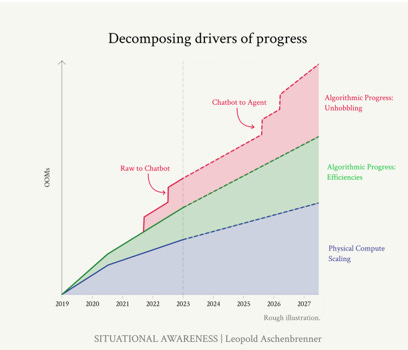
This is an ongoing development. Microsoft CTO Kevin Scott illustrated the growth in compute power at the Microsoft Build event on May 21, 2024. Unable to share specific numbers, he used marine animals for comparison, as one does… His message, as I interpret it, suggests that the compute power for GPT-3, GPT-4, and GPT-5 is in the ratio of 1:5:100. [The text in yellow is added by me, for clarity.] Thus, we can expect GPT-5 to be trained on 20 times the compute of GPT-4. This estimate does not account for any algorithmic efficiencies or unhobbling.

Combining the increase in compute with estimated algorithmic efficiencies, GPT-5 could be about 2 OOMs, or 100 times, more powerful than GPT-4. No one, not even OpenAI, knows exactly what this will mean. This potential leap is often overlooked, even in research papers in areas such as economics, implicitly assuming close to zero progress in AI development.
There is a natural reason why it might feel like progress has stalled, though. The capabilities of AI models typically improve in a stepwise fashion, roughly every two years. Since we are now 1.5 years into the GPT-4 era, we haven't seen a model pushing the technical boundaries for a while. Although GPT-4 has improved significantly, OpenAI has prioritized making the model smaller and more efficient rather than enhancing its intelligence. Based on pricing and response times, I estimate that the GPT-4o model is about 5x smaller than the original GPT-4 0314 model.
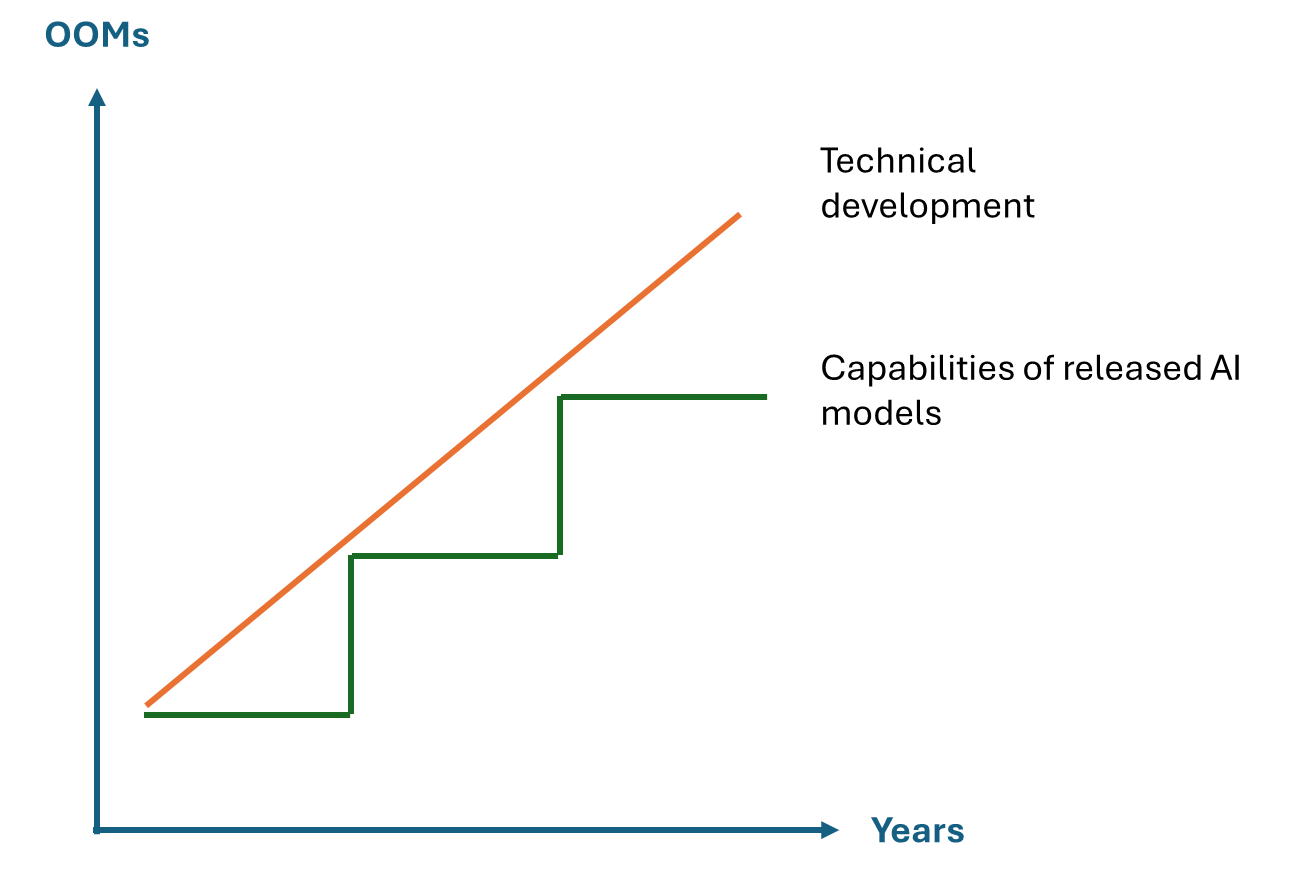
Are We Already Seeing Indications of a Slowing Development Pace?
The problem with exponential growth is that it cannot continue indefinitely. For instance, if a computer's size doubled annually, by year 90, it would surpass the size of the known universe. Eventually, exponential growth tends to transition into s-curves. The key question is when this transition will occur.
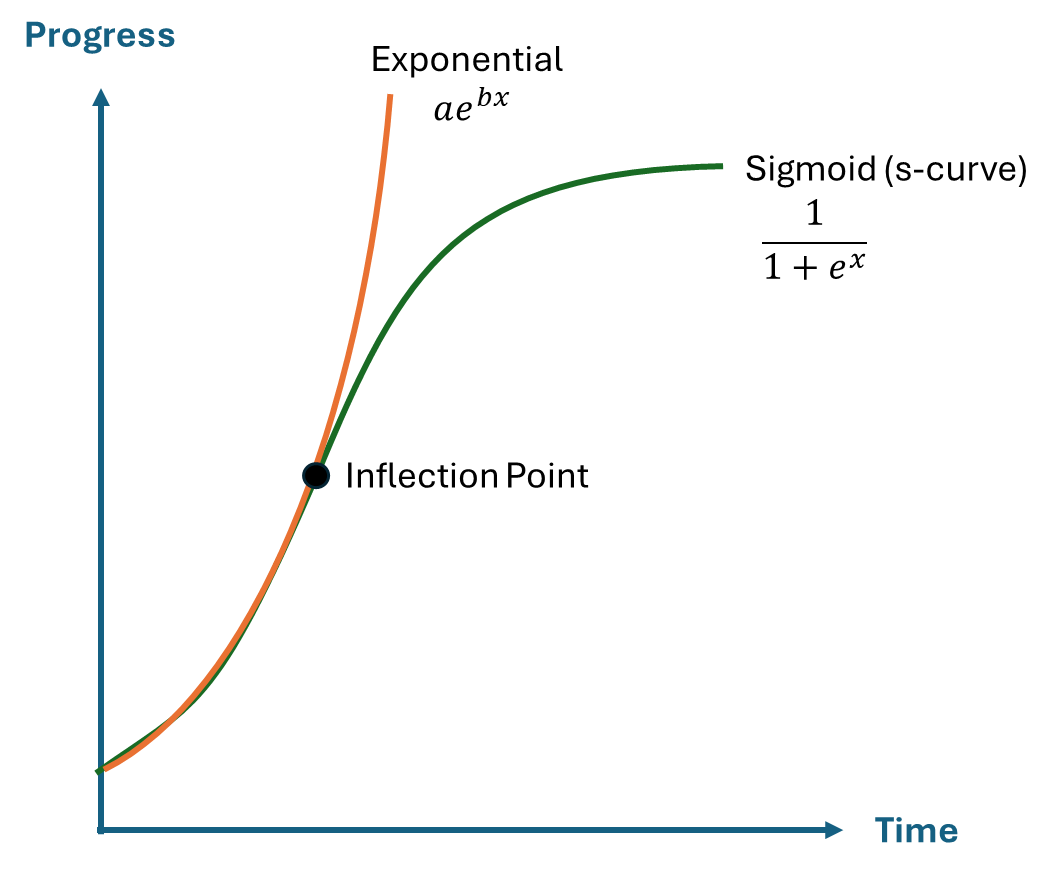
Both Microsoft and OpenAI assert that there are no indications we are nearing an inflection point. Others argue that we have already passed it. Even prominent AI insiders have expressed low expectations for the development pace, often without substantial analysis, facts, or data to support their views, though.
There are clear physical constraints on the exponential growth of AI systems, for example, related to compute power and energy. The data centres planned for 2028 and beyond are projected to require energy in the gigawatt range, comparable to the output of a nuclear reactor. Scaling to such levels will be challenging. Each new frontier model demands resources akin to the world’s largest data centre, making it technically feasible but logistically daunting to build them within a predetermined, short timeline, even with sufficient funding. Therefore, I anticipate delays in future models due to construction delays in these data centres.
Another significant limitation is access to data for training the models, known as the "data wall." Current models have already utilized most of the available information on the internet. While multimodal models can expand their data sets by incorporating video, scaling beyond this point will be difficult. Future models will have to rely heavily on AI-generated, or synthetic, data. This approach has shown promise, as seen with Google’s AlphaZero, and while I am optimistic about its large-scale application, there are no guarantees.
A critical question remains: even if the next model is 100x more powerful than GPT-4, will it be any smarter in practice? This is unknown. Diminishing returns suggest that the next OOM increase in size may not impact intelligence as much as the previous OOM did. However, historically, scaling has consistently led to improvements and new, unexpected, emergent capabilities.
In the end, it comes down to fundamental assumptions. My view of how LLMs and multimodal models work is that they work through compression. They compress all human knowledge, or at least the information available on the internet, into a relatively small set of numbers. They achieve this by developing a world model that emerges from the data, enabling an understanding of the world, including laws of nature and human behaviour. Many AI researchers, particularly those at OpenAI, share this perspective. However, some researchers argue that LLMs are fundamentally incapable of creating world models, suggesting that their capabilities are merely based on pattern matching and memorization. I think the evidence contradicts this view. However, if proven true, the transformer-based architecture underpinning current models could be a dead end, and progress would stall. As soon as we get the next generation of models, we will know for sure.
What We Can Expect From GPT-5
Sam Altman has indicated that the transition from GPT-4 to GPT-5 will be as significant as the leap from GPT-3 to GPT-4. Remember, when GPT-3 was launched, it could only continue writing a given text, and the continuation often barely made sense.
Assuming the new user interface has already been revealed, you might not initially notice a significant difference with GPT-5. This is often the case with new generative AI models. However, users will soon showcase remarkable results to specific questions, motivating some to claim that GPT-5 is Artificial General Intelligence (AGI). OpenAI would likely refute such claims. They have a strict contractual definition of AGI in their contracts with Microsoft and investors, stipulating that agreements cease once the AGI threshold is met. I guess that OpenAI might even dumb down the model to avoid jeopardizing that limit.
OpenAI also has a high threshold for what it consider AGI. According to Altman, an AGI should be able to drive AI development research, which he says is not expected to be possible with GPT-5. He believes that one to two additional breakthroughs, and more scale, are needed to reach AGI. Best case, this could be achieved with a "GPT-6" in 2027.
To understand where we are today and what we might expect in the next three years, I have compiled my current estimates in areas where models today are weak or lack capabilities. Note that my conviction level for these estimates is low, and I anticipate frequent and significant revisions. It's also possible that OpenAI could be surpassed during this period by Google DeepMind, Anthropic, or, less likely, a challenger such as Meta, Nvidia, or Elon Musk’s xAI.

I anticipate the most significant difference with GPT-5 will be its functionality, resembling more of an agent than the foundational models we've seen so far. In a foundational model, users interact directly with the model. However, with GPT-5, while it may seem like direct interaction, numerous processes will be occurring in the backend. Various multimodal models (and possibly other tools) will be employed for different purposes. For simple questions, a small, fast, and cost-effective model will be utilized. For complex tasks, multiple models might collaborate to plan, search the web, and generate various answer options, for example using Monte Carlo simulations. There might be distinct models for memory management and multimodality, including generating images and short movies.
However, I do not expect a full-scale agent architecture yet, which would include features like an internal clock to solve tasks continuously 24/7 or the ability to generate videos of potential scenarios for internal use, akin to human predictions. Such features will likely require GPT-6, due to their heavy compute demands.
Even if GPT-5 doesn’t feature a complete agent architecture, it will still significantly impact corporations if my predictions hold true. While GPT-4 in business use cases mostly acts like an advanced Google search, GPT-5 will enable building agents on top of it and introduce new use cases, allowing it to solve more types of general-purpose tasks.
The task of writing computer code is at the forefront of agent development, providing a sneak peek into what will be possible in other areas during the second half of the year. In my last article, I discussed Devin, the coding agent. I expect to see similar agents for other business tasks, such as marketing, business controlling, and business intelligence. Furthermore, I anticipate that coding agents powered by GPT-5 will perform at the level of developers with several years of experience.
Copilots vs. Agents: A Contrarian Perspective
In the area of agents, I hold a contrarian view, and I have recently revised my thinking. In my last article, I discussed the race between "copilots" that enhance humans and "agents" that replace them. The prevailing belief is that copilots will enter the market first, while agents remain a distant future development. Listening to companies like Microsoft, one might believe that AI will solely enhance human capabilities without ever replacing them.
Previously, I described this evolution in phases: starting with foundational models, then integrating them into tools to create copilots, followed by AI agents, and finally, integrated systems of AI agents. I now question the order of these phases.
This is because integrating AI into existing tools to create copilots might be more challenging than expected. While adding AI as an advanced search feature might be straightforward, rebuilding software that has been developed over 35 years, like Microsoft's Office tools, to become "AI first" is challenging. Paradoxically, it might be faster to build AI agents to meet business needs.
If this holds true, it will impact every company’s AI strategy (refer to my article 'Thinking About Developing an Artificial Intelligence Strategy?'). Copilots can be implemented in a decentralized way, allowing trials in specific units where the benefits are high, with the main concern being model sourcing. However, AI agents are different. They more resemble Robotic Process Automation (RPA), which automates repetitive, rules-based tasks using software robots, or "bots," that mimic human interactions with digital systems.
RPA became popular in the mid-2010s with advancements in machine learning, designed to streamline workflows, reduce errors, and increase efficiency across various industries. Both RPA and AI agents require a platform for operation, similar to managing employees. They need email addresses, access to data sources, and adherence to corporate guidelines and policies. There must also be structures for decision-making and financial management—who decides when RPA can be used, and who pays for it. The decentralized approach suitable for copilots is less appropriate here.
It might make sense to let the organization that manages RPA also manage AI agents or establish a new organization for this purpose. This structure needs to be scalable. While you might start with a few AI agents, their numbers could quickly surpass those of employees if the cost is sufficiently low.
Recommendations
Given the limited value of current models outside specific use cases, and the ongoing development of new models, I continue to advocate for a balanced and pragmatic approach to corporate AI adoption. Companies should develop a diverse portfolio of AI initiatives, combining 'no-regret' moves with some higher-risk, high-reward ventures.
As detailed in my article 'Thinking About Developing an Artificial Intelligence Strategy?', the critical areas of focus are:
Building the foundation for using AI
Incorporating AI into ongoing digitalization efforts or digital transformations
Improving everyday efficiency with AI, including executive decision-making
'No-regret' initiatives primarily involve formulating a comprehensive AI strategy, focusing on foundational development, and enhancing operational efficiency. Practically, this means ensuring widespread access to AI models and providing training for employees to streamline meetings, expedite email and report writing, and enhance overall productivity. These strategies are likely to produce tangible benefits from day one.